Advancements In Computer Vision Models For View Synthesis: A Survey
Abstract
In this post I survey a collection of Computer Vision Models that have made key advancements for View Synthesis. The fundamental idea behind View synthesis is the ability to take two-dimensional images, or videos, from different camera viewpoints and construct realistic novel views from them. Being able to synthesize a realistic novel view can depend on many factors such as, sufficient input images across various viewpoints and quality or resolution of the provided images. I will be only discussing models that have produced satisfactory results given their set of input and test images. Specifically, I have researched SRN (Scene Representation Networks), NeRF (Neural Radiance Fields), and NeuMan (Neural Human Radiance Field From a Single Video). Each of the aforementioned models have demonstrated great strides in the field of Computer Vision but also have their own set of trade-offs. My method of evaluation is based on the approach, improvements/limitations and level of detail in the realistic scenes produced. As a supplement, and due to the great model improvements over the past few years, it is constructive to discuss potential applications for this technology. It is my general observation that each model introduced builds upon and improves the strengths of the previous model making way for new applications and innovations to occur.
Note: This post is a condensed version of the full survey.
Background
In just the past decade we have observed incredible advances in machine learning (ML). With that, several major areas have seen breakthroughs and key advancements, such as the field of Computer Vision. It was not until the later parts of the decade of the 2000s, after two more decades of computational performance improvements driven by Moore’s Law that computers finally started to become powerful enough to train large neural networks on realistic, real- world problems like Imagenet [1].
In the same way, the subfield of Computer Vision has also seen advances in View Synthesis–the three models (SRN, NeRF and NeuMan) I discuss in this post were introduced in 2019, 2020, and 2021–respectively. As one can imagine being able to accurately synthesize novel views is a challenging task with many considerations to account for, such as image lighting, 3D object, translucency, and texture. As these models are only one year apart and yet the technological advancements are fascinating and take us to a new era of View Synthesis.
This survey provides an intuition about the models, understand- ing of their key advancements and the types of results each are capable of producing. To gain deeper algorithmic understanding of each of these models I will defer the reader to the papers cited. [9] [7] [4]
NEURAL RADIANCE FIELDS
Neural Radiance Fields (NeRF) takes in a sequence of input images and optimizes a volumetric scene to synthesize novel views. This is achieved by using a neural network that encodes a continuous and volumetric representation of the scene.
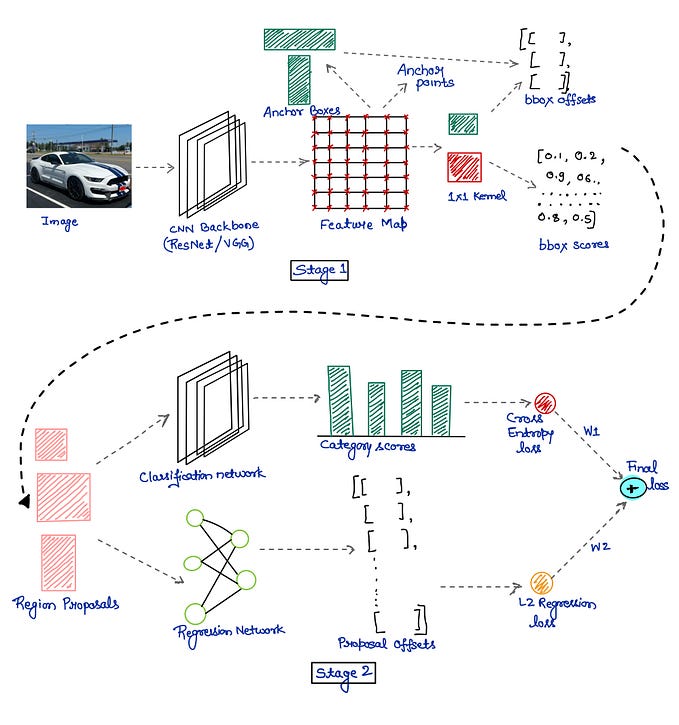
A scene is represented as a continuous 5D function that outputs the radiance emitted in each direction (𝜃,𝜙) at each point (𝑥,𝑦,𝑧) in space, and a density at each point which acts like a differential opacity controlling how much radiance is accumulated by a ray passing through (𝑥,𝑦,𝑧) [7].
The image below gives us a good intuition about what is going on. Essentially, the model passes in the discrete points along the array from the two camera view points (left-hand side of the image) and we pass it into our model which outputs view dependent colors and volume densities (right-hand side of the image). The model 𝐹𝜃 is a fully-connected neural network with 9 layers using 256 channels. [7] From there, the colors along the array are combined to compute the final single color for each pixel.
In contrast to SRNs, one of the key benefits that NeRF provides is how it minimizes the cost of storage needed–this is seen in comparison to a discretized voxel grid when working in higher resolutions. To achieve this efficiency, NeRF uses a positional encoding to map each input 5D coordinate into a higher dimensional space, which enables us to optimize neural radiance fields to represent high frequency scene content. [7]. Hence, as we scale up we marginally affect storage space requirements which is critical when working with high resolution imagery.
Results
I was able to train a small set of data of 16 images taken from an iphone (each image roughly 1.5mb). For preprocessing we can recover camera poses from this section of the Local Light Field Fusion repo.
Environment
- Distributor ID: Ubuntu
- Description: Ubuntu 22.04.1 LTS
- Release: 22.04
- Codename: jammy
Project leverages nvidia-docker, if setup appropriate you can run the following command to check:
docker run --rm --gpus all nvidia/cuda:11.6.2-base-ubuntu20.04 nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 520.61.05 Driver Version: 520.61.05 CUDA Version: 11.8 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... On | 00000000:01:00.0 Off | N/A |
| N/A 44C P8 7W / N/A | 2432MiB / 8192MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+Test images:



Result video:

With NeRF, I have observed quite remarkable realistic novel views created from a set of input images. Not only is NeRF generating realistic images with this approach but it also is considered storage and computationally efficient. In addition, the novel views in NeRF produce much more realistic results with greater attention to detail compared to SRNs. Although NeRF performs quite well it is important to note that it only performs well on the images that have been provided and will not do well as a generalized solution–it will fail on new and untrained environments.
Limitations
• Although NeRF requires minimal storage requirements it has slow/costly training times.
• Generalizability–NeRF only handles static scenes (which cannot be reused in difference or similar scenes).
• Some difficulty with translucency.
NEURAL HUMAN RADIANCE FIELD FROM A SINGLE VIDEO
Neural Human Radiance Field from a Single Video (NeuMan) builds high quality renderings of human under novel poses and its environment from just a single video instead of static images that were used in SRNs and NeRF. NeuMan combines and trains two NeRF models (a human NeRF model and a scene NeRF model). [4] With training videos as short as 10 seconds this model can generate high quality renderings of the human under novel poses and across different novel views composed together. This approach is also quite impressive due to the fact that only a single video is provided without multi-camera setup or additional annotations provided which has been a prerequisite for SRNs and NeRF.
For scene reconstruction, NeuMan extracts background pixels only and learns the geometry of the scene while extracting the human out of it. For human reconstruction, Neuman learns an animatable human model with realistic details. [4] This model captures the texture, pattern, and objects on clothing quite well and beyond what we see with Skinned Multi-Person Linear model ((SMPL) a skinned vertex based model that accurately represents a wide variety of body shapes in natural human poses [6]).
Combining the background scene and the human, NeuMan produces high quality renderings of novel human poses in motion (rotations, cartwheels, jumping, etc.,) demonstrating the new unseen poses. Furthermore, the model has the ability to render reposed humans together with the scene–i.e., telegathering. [4]
Observing NeuMan I found that it can, quite effectively, generate novel human poses in a novel scene with a short single video. It is also impressive how we can have multiple humans composed together (telegathering) in novel poses. Although the goal here is a little different from previous models examined, the ground work laid by NeRF is prevalent throughout NeuMan’s implementation.
Limitations
- The dynamics beyond SMPL[6] cannot be modeled without static NeRF [7], those dynamics will degenerate to average shape or color–more expressive body models are required [4]
- The human always has at least one contact point with the ground to estimate the scale relative to the scene–hence, smarter geometric reasoning is needed for videos with jumping or uneven group [4]
- Only a single human being is assumed to be in the scene.
APPLICATIONS
View Synthesis has seen rapid growth in the past decade and with NeRF coming onto the scene in 2020 we have seen an explosion of new models that leverage the foundations of this model (as seen in NeuMan [4]). This being said, there are quite a few applications that comes to mind where we can leverage these models–the following list names a few:
- 3D geometric mapping for robots (this could be a robots state in which it operates under)
- Grasping transparent objects for cleanup or packaging (Dex-NeRF [3] builds upon NeRF to be able to handle this)
- Cheap storage of novel views
- Virtual reality
- Video Enhancements
Conclusion
In all, this survey has provided insight into three approaches to producing realistic scenes using View Synthesis models in computer vision. Each approach seems to build upon the previous findings and propel the field to new opportunities.
With SRN, we saw single-observation image reconstruction that yields novel views and geometric representations. However, downsides of this approach can come with storage of the voxel grid. With NeRF, we solve this problem and efficiently so–we are able to create much more realistic novel views with a handful of images. NeRF utilizes a 5D input function that consists of (𝑥,𝑦,𝑥,𝜃,𝜙), where (𝑥,𝑦,𝑧) is the spatial location and (𝜃,𝜙) is the viewing direction. [7] From there, NeRF efficiently maps this out to produce pixel values for our end result. The Downsides of NeRF consist of training time, handling translucency, and generalizability. Lastly, NeuMan took the best of the previous findings and builds a model to learn from a single video and capture the environment as well as the human in the environment to create and compose novel scenes. From there, Neuman demonstrates the capability of generating novel scene backgrounds, novel poses, and telegathering by way of composition.
View Synthesis continues to rapidly grow as a subfield of Computer Vision–I have presented a select few of the latest models that have generated a lot of interest and attention. I will list a couple more models that the reader can check out as a supplement.
- Plenoxels: Radiance Fields without Neural Networks: Plenoxels represent a scene as a sparse 3D grid with spherical harmonics. Plenoxels are optimized two orders of magnitude faster than Neural Radiance Fields with no loss in visual quality. [11]
- Light Field Neural Rendering (LFNR): LFNR operates
on a four-dimensional representation of the light field, the model learns to represent view-dependent effects accurately. [10] - Urban Radiance Fields: Urban Radiance Fields is able to perform 3D reconstruction and novel view synthesis from data captured by scanning platforms commonly deployed for world mapping in urban outdoor environments (e.g., StreetView). [8]
- Panoptic Neural Fields: A Semantic Object-Aware Neural Scene Representation (PNF): PNF is an object-aware neural scene representation that decomposes a scene into a set of objects (things) and background (stuff). [5]
Liked the author? Connect with Gabriel Sena
Let’s continue the conversation! You can find me on LinkedIn.
- 👏 Clap if you enjoyed reading and follow for more content!
- ☕️ Buy me a coffee to keep me going
- 👉 Subscribe to keep up with the latest content!
- Feedback and comments are greatly appreciated 🙏
References
[1] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. ImageNet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition. 248–255. https://doi.org/10.1109/CVPR.2009. 5206848
[2] John Hart. 1995. Sphere Tracing: A Geometric Method for the Antialiased Ray Tracing of Implicit Surfaces. The Visual Computer12(061995). https://doi.org/ 10.1007/s003710050084
[3] Jeffrey Ichnowski, Yahav Avigal, Justin Kerr, and Ken Goldberg. 2021. Dex- NeRF: Using a Neural Radiance Field to Grasp Transparent Objects. (2021). https://doi.org/10.48550/ARXIV.2110.14217
[4] Wei Jiang, Kwang Moo Yi, Golnoosh Samei, Oncel Tuzel, and Anurag Ranjan. 2022. NeuMan: Neural Human Radiance Field from a Single Video. (2022). https://doi.org/10.48550/ARXIV.2203.12575
[5] Abhijit Kundu, Kyle Genova, Xiaoqi Yin, Alireza Fathi, Caroline Pantofaru, Leonidas Guibas, Andrea Tagliasacchi, Frank Dellaert, and Thomas Funkhouser. 2022. Panoptic Neural Fields: A Semantic Object-Aware Neural Scene Represen- tation. (2022). https://doi.org/10.48550/ARXIV.2205.04334
[6] Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J. Black. 2015. SMPL: A Skinned Multi-Person Linear Model. 34, 6 (oct 2015), 248:1–248:16.
[7] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. 2020. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. (2020). https://doi.org/10.48550/ARXIV.2003.08934
[8] Konstantinos Rematas, Andrew Liu, Pratul P. Srinivasan, Jonathan T. Barron, Andrea Tagliasacchi, Thomas Funkhouser, and Vittorio Ferrari. 2021. Urban Radiance Fields. (2021). https://doi.org/10.48550/ARXIV.2111.14643
[9] Vincent Sitzmann, Michael Zollhöfer, and Gordon Wetzstein. 2019. Scene Repre- sentation Networks: Continuous 3D-Structure-Aware Neural Scene Representa- tions. (2019). https://doi.org/10.48550/ARXIV.1906.01618
[10] Mohammed Suhail, Carlos Esteves, Leonid Sigal, and Ameesh Makadia. 2021. LightFieldNeuralRendering.(2021). https://doi.org/10.48550/ARXIV.2112.09687 [11] Alex Yu, Sara Fridovich-Keil, Matthew Tancik, Qinhong Chen, Benjamin Recht, and Angjoo Kanazawa. 2021. Plenoxels: Radiance Fields without Neural Networks. (2021). https://doi.org/10.48550/ARXIV.2112.05131